4025 River Mill Way Mississauga, ON L4W 4C1, Canada
India
4A, Maple High Street Hoshangabad Road, Bhopal, MP
UAE
Office 47, Oud Mehta Tower, 9th Floor, Next to Wafi City, Umm Hurair Second, Dubai, UAE
Realistic Human Speech Generation: How AI TTS & Voice Cloning Models Are Redefining Voice
Over the last decade, conversational systems have evolved from simple command-based interfaces to fully interactive agents capable of engaging users through natural dialogue. A major factor influencing this evolution is the advancement in AI voice generation
and
speech synthesis
, where the goal is no longer just intelligibility, but realism, emotion, and responsiveness.
Conventional text-to-speech software delivers fast responses but often lacks natural prosody and human-like expression. On the other hand, modern neural text-to-speech models generate highly realistic output but introduce latency that disrupts real-time interaction. This latency-versus-quality trade-off remains one of the core challenges in AI text to speech systems.
This white paper presents a practical and production-ready approach using XTTS v2, a generative AI voice cloning model, to achieve human-like text to speech while maintaining conversational latency suitable for real-world applications such as travel assistants, call automation, and voice-driven interfaces.
RELATED WORK
Research in AI speech synthesis has progressed rapidly with the introduction of deep learning based architectures such as Tacotron, VITS, and transformer-based autoregressive models. Early systems focused primarily on clarity, while recent work emphasizes natural sounding AI voice, emotional control, and speaker similarity.
Voice cloning technology gained attention through projects such as Tortoise TTS and later evolved into more efficient systems capable of zero-shot inference. Public datasets like Common Voice and LibriTTS have played a key role in accelerating research by providing large-scale, high-quality speech data.
Despite these advances, many systems struggle with real-time deployment due to computational constraints. This limitation has pushed the industry toward GPU-accelerated pipelines and mixed-precision inference, which form the foundation of modern AI TTS deployments.
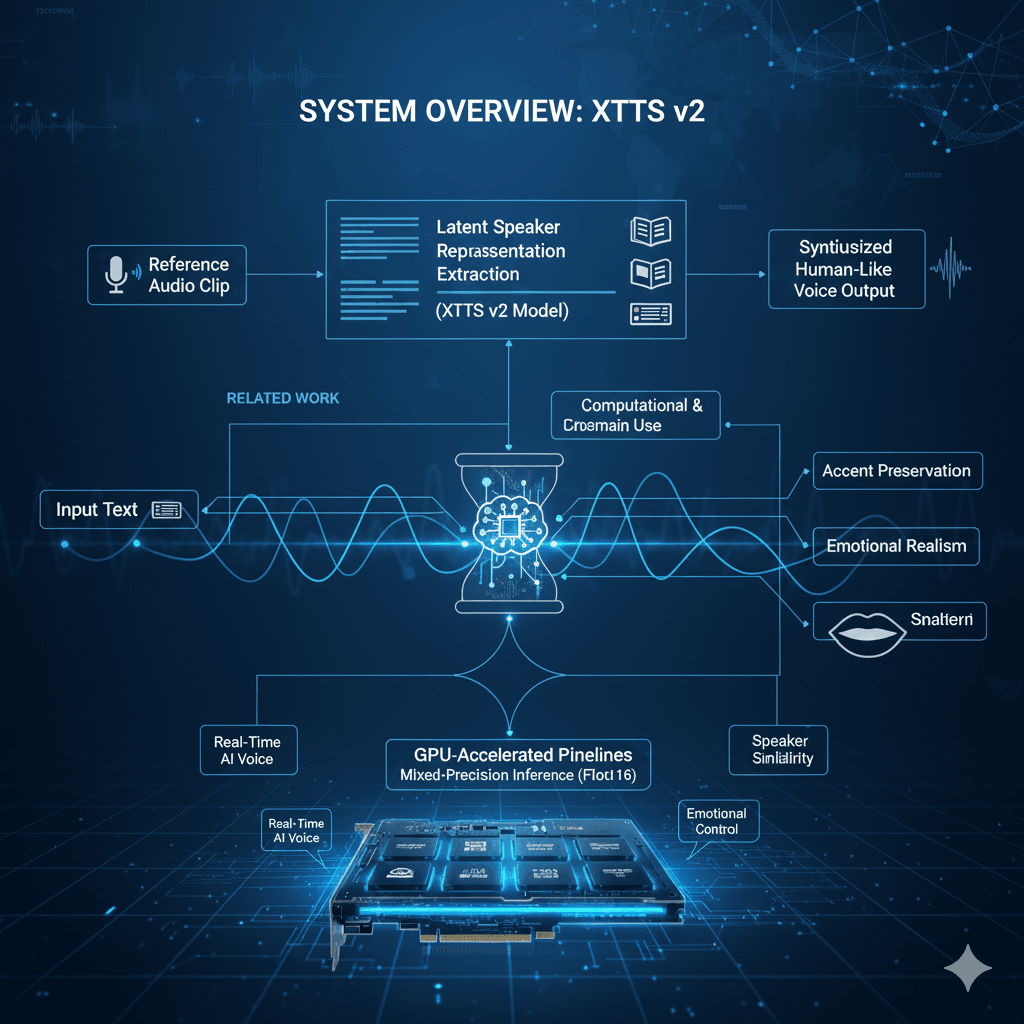
SYSTEM OVERVIEW: XTTS v2
XTTS v2 is a generative AI voice synthesis model designed to replicate a speaker’s voice using only a short reference audio clip. Unlike traditional speech synthesis pipelines, XTTS does not rely on pre-trained voices or lengthy fine-tuning by default.
The system operates by extracting latent speaker representations from reference audio and conditioning the speech generation process on both text and these speaker embeddings. This approach enables voice cloning AI with strong accent preservation and emotional realism, making it suitable for multilingual and cross-domain use cases.
TECHNICAL ARCHITECTURE
Generative Voice Cloning Pipeline
The XTTS pipeline begins with text normalization and tokenization, followed by latent extraction from the reference audio. These latents encode speaker-specific features such as pitch, timbre, and speaking style. During inference, the model predicts audio frames conditioned on both linguistic content and speaker identity, enabling realistic AI voice output without retraining.
This design allows rapid persona switching and supports conversational agents where flexibility is essential.
IMPLEMENTATION ON CPU VS GPU
CPU-Based XTTS Inference
XTTS can technically run on a CPU, but this approach is limited to offline or experimental use. CPUs are optimized for sequential logic rather than the large-scale matrix operations required for neural text-to-speech models. As a result, generating one second of speech can take several seconds, making real-time AI speech generation impractical.
CPU inference may be acceptable for batch audio generation, testing environments, or research validation, but it fails to meet the latency requirements of conversational systems.
GPU-Based XTTS Inference
GPU deployment transforms XTTS into a real-time engine. By leveraging CUDA acceleration and mixed-precision computation, XTTS achieves faster-than-real-time synthesis. The use of Float16 inference significantly reduces memory usage while maintaining output quality, allowing modern GPUs to handle AI voice workloads efficiently.
For any production-grade text to speech AI system, GPU inference is not optional—it is essential.
PRECISION OPTIMIZATION WITH FLOAT16
Mixed-precision inference plays a crucial role in enabling real-time AI voice generation. By using 16-bit floating-point values instead of 32-bit, XTTS reduces VRAM consumption and benefits from specialized GPU hardware such as Tensor Cores.
Critical layers, including normalization layers, are retained in full precision to preserve numerical stability. This balance ensures that natural sounding AI voice output is achieved without sacrificing performance.
HYBRID TALKING BOT ARCHITECTURE
To deliver a smooth conversational experience, XTTS is best deployed within a hybrid architecture.
Pre-generated phrases such as greetings and fillers provide instant feedback, while dynamic responses are synthesized through streaming inference. By beginning playback as soon as the first sentence is generated, perceived latency is dramatically reduced.
Additionally, incorporating voice activity detection enables interruption handling, allowing the system to respond naturally when users speak mid-response. This design closely mirrors human conversational behavior and elevates the realism of AI voice synthesis.
DATA STRATEGY AND FINE-TUNING
While zero-shot voice cloning offers flexibility, fine-tuning remains the most reliable approach for long-term deployments. Training XTTS on 20–40 minutes of clean, professionally recorded audio stabilizes pronunciation, pacing, and emotional delivery.
Public datasets hosted on Hugging Face and OpenSLR provide valuable resources for experimentation, while custom recordings offer maximum control for branded or persona-specific assistants.
RESULTS AND OBSERVATIONS
Deployments using GPU-accelerated XTTS with streaming inference consistently achieve sub-second response times. Users perceive interactions as fluid and human-like, with significant improvements over traditional text-to-speech software.
The combination of neural text-to-speech, optimized hardware usage, and hybrid orchestration establishes XTTS as a strong foundation for scalable conversational AI systems.
XTTS v2 demonstrates that high-quality AI text to speech and real-time performance are no longer mutually exclusive. By combining AI voice cloning, GPU acceleration, and hybrid streaming architecture, conversational systems can achieve both realism and responsiveness.
This approach represents a practical path forward for organizations seeking to deploy human-like AI voice solutions at scale.